DeepSeek V3.2 and V3.2-Speciale are now available in Cline
DeepSeek's new reasoning-first models are live. V3.2 for daily agentic coding; V3.2-Speciale for maximum reasoning power. Both at $0.28/$0.42 per million tokens.


DeepSeek-V3.2 and DeepSeek-V3.2-Speciale are now available through Cline. These are DeepSeek's first models designed specifically for agentic workflows (like Cline), with reasoning integrated directly into tool execution rather than treated as a separate step.
V3.2 is the daily driver, while V3.2-Speciale is for when you need maximum reasoning power on hard problems.
What's new in V3.2
DeepSeek-V3.2 introduces DeepSeek Sparse Attention (DSA), an efficient attention mechanism that reduces computational costs while maintaining quality in long-context scenarios. The technical report covers the architecture in detail.
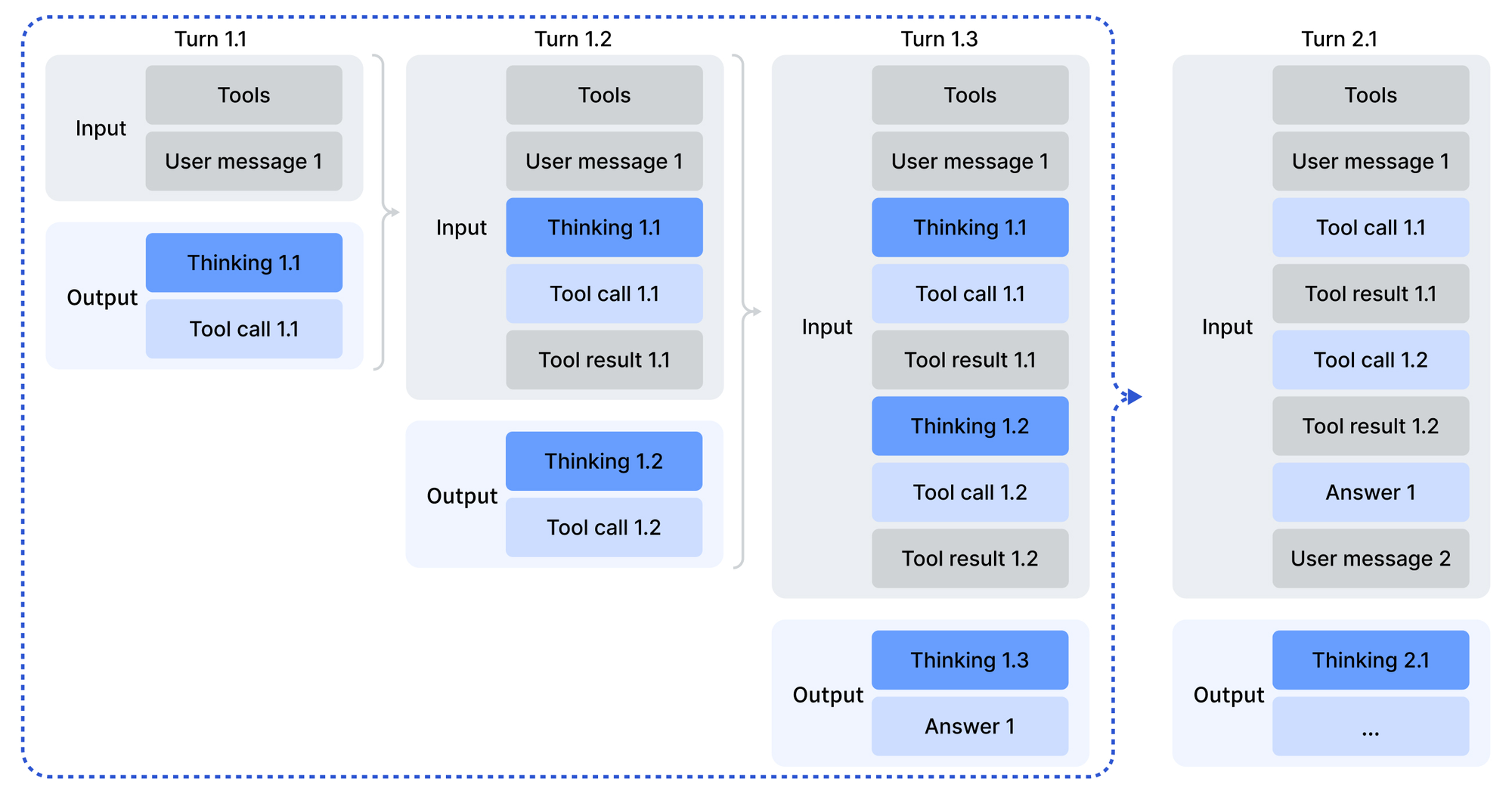
The key innovation is "thinking in tool-use." Previous models reason first, then execute tools. V3.2 reasons while executing tools, maintaining its chain of thought across multiple tool calls within a tool execution. This matters for Cline because agentic coding involves constant tool execution; reading files, writing code, running commands, checking results.
Importantly, V3.2 retains reasoning traces across tool calls until a new user message arrives. Tool outputs alone don't trigger a context wipe. For workflows where you're doing read → edit → run → check cycles, the model keeps its reasoning thread intact rather than re-deriving context on each step. This is similar to interleaved thinking, which Minimax introduced with minimax-m2.
DeepSeek trained V3.2 on 1,800+ synthesized environments and 85,000+ complex agent instructions. The breakdown: 24,667 code agent tasks, 50,275 search agent tasks, 5,908 code interpreter tasks in real Jupyter environments, and 4,417 general agent tasks. This scale of agent-specific training data is what enables the model to generalize across different tool-use scenarios.
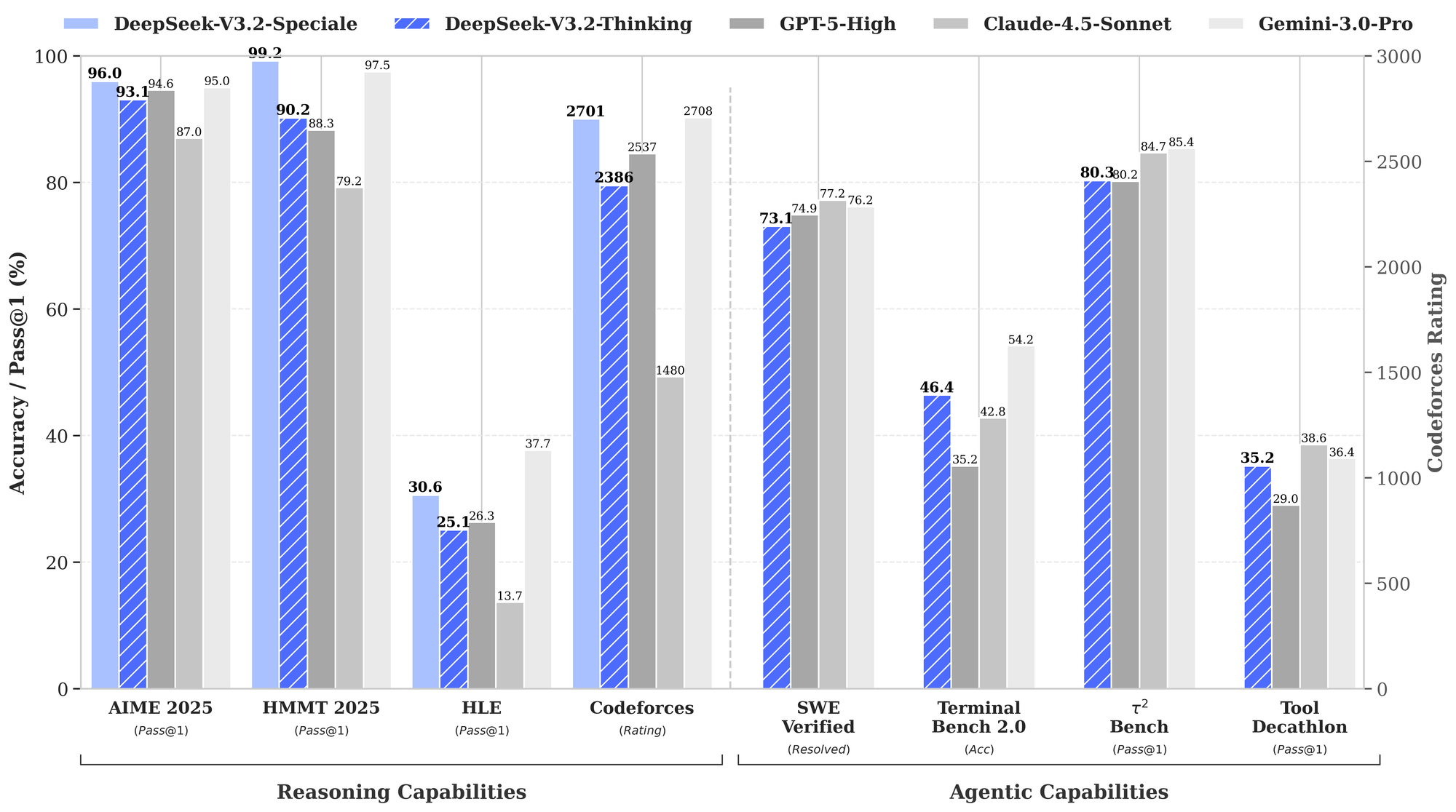
DeepSeek also invested heavily in post-training. They allocated over 10% of pre-training compute to reinforcement learning, which is unusually high. That's a key reason an open-source model performs at the GPT-5 class on reasoning benchmarks.
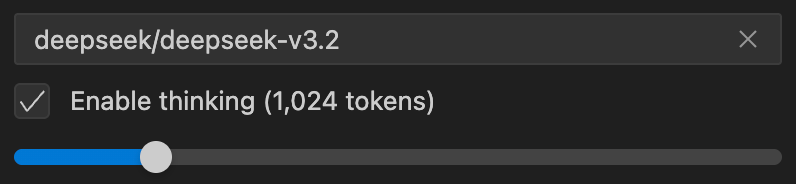
You can control reasoning behavior by enabling thinking and setting the slider.
When to use which
V3.2 is the balanced option. Use it for everyday coding tasks where you want solid reasoning without excessive token usage. It aims for the sweet spot between inference quality and response length.
V3.2-Speciale is the high-compute variant with relaxed length constraints. Use it when you need maximum reasoning depth on genuinely difficult problems. DeepSeek reports gold-medal performance on the 2025 IMO, IOI, ICPC World Finals, and CMO using this variant.
The tradeoff is token efficiency. Speciale uses significantly more output tokens to reach its conclusions. V3.2 is more constrained and practical for most daily work.
Specs and pricing
Both models share the same pricing and context window:
- Input: $0.28 per million tokens
- Output: $0.42 per million tokens
- Context window: 131K tokens
Limitations to note: neither model supports images, browser use, or prompt caching. The 131K context window is smaller than Claude's 200K or Gemini's 1M+, so you'll hit limits faster on large codebases.
Try it now
Both models are available in the Cline provider dropdown. Select DeepSeek-V3.2 for daily use or V3.2-Speciale when you need to throw maximum reasoning at a problem.



