How I Learned to Stop Course-Correcting and Start Using Message Checkpoints
Why hitting the reset button will actually save you time instead of fighting an upstream context current.


You're ten messages deep with Cline. What started as a simple task – "add authentication to this Express app" – has somehow morphed into a sprawling mess where the model is suggesting OAuth implementations when you just needed basic JWT, restructuring your entire database schema, and confidently explaining why you should migrate to microservices. You know exactly what went wrong: somewhere around message three, when you said "make it secure," the model veered off into enterprise-grade architecture territory.
Your instinct is to course-correct. "No, let's keep it simple. Just JWT. Remember the original requirements." But each correction seems to dig you deeper. The model acknowledges your feedback, considers some of it, building on its own previous suggestions rather than truly reconsidering. You're not collaborating anymore; you're wrestling.
But what if you could go back in time to the exact moment the conversation went wrong, rewrite your prompt, and try again? Here's what's actually happening, and why this "conversational time travel" is the right approach.
LLMs like happy paths
Recent research from Laban et al. reveals something fundamental about how LLMs process information: they experience a 39% average performance drop when instructions are delivered across multiple conversation turns compared to receiving complete context upfront. And while the paper's simulation uses a simplified version of a real-world dialogue, its findings are profound: if models struggle with clean, sequential information, they will struggle even more with the messy, back-and-forth nature of a true creative or debugging session.
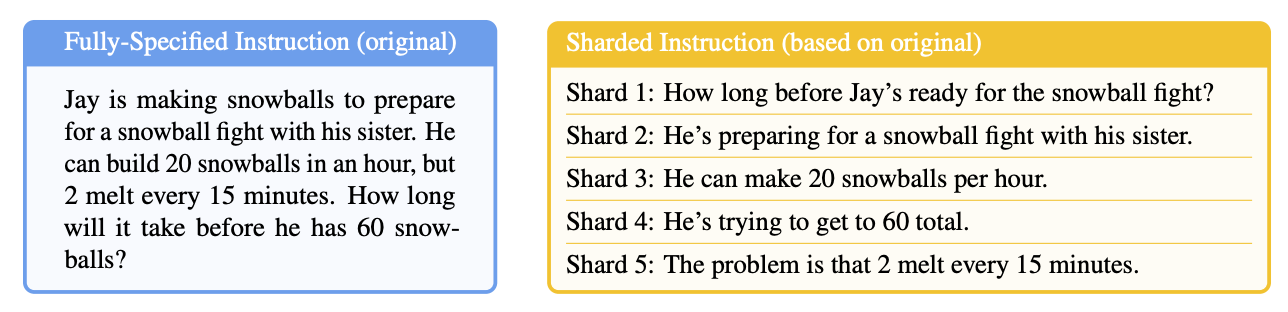
LLMs are optimized for what we can call the "happy path" – a clear trajectory from comprehensive input to desired output. This is why course-correction feels like fighting the current. You're not just providing new information; you're asking the model to unlearn its previous assumptions while simultaneously building on them. The research shows this simply doesn't work well. When the same fragmented instructions were consolidated into a single prompt, performance jumped back to 95% of optimal.
This isn't just an academic finding; it's a reality recognized by other expert AI teams. Engineers at Anthropic, for instance, advise treating Claude Code like a "slot machine": save your state, let it run, and if the result isn't a jackpot, you start fresh rather than trying to wrestle with corrections. This practical advice perfectly mirrors the research: starting over has a higher success rate than trying to fix a model's mistakes mid-conversation.

Course-correcting is an uphill battle
The key insight isn't that LLMs inevitably deteriorate. The issue is that once you've left the happy path, getting back on it through conversation is like trying to merge back onto a highway from a field. The model's context is now polluted with:
- Its own generated assumptions and explanations
- Your corrections and clarifications
- The implicit validation of parts you didn't correct
- Increasingly verbose attempts to reconcile conflicting information
Each message adds more context pollution. You're not debugging code; you're trying to debug a conversation, and conversations don't have clean stack traces.
Hacking the happy path with checkpoints
A workflow built around Cline's message checkpoint system solves this. It’s not just about undoing file changes; it’s about rewinding the conversation itself. When you edit a previous message in Cline, you're given the option to restore the task's state to the moment right before that message was sent. This is how you engineer your own happy path.
Here's how it works in practice:
- You recognize the off-ramp. The moment you think "oh, this is not what I wanted" -- that's your signal. Not to correct, but to find the message that sent things sideways.
- You learn from the deviation. The model's misunderstanding is valuable data. It shows you what context was missing from your original prompt.
- You rewrite the divergent prompt. Instead of trying to steer back, you find the exact message in the chat where the conversation went off track. You edit that prompt to include the missing context or clearer instructions.
- You restore the context. After editing the message, Cline presents you with the option to restore the state. You choose to "Restore All", which resets the model's context to that point, erasing the subsequent "polluted" conversation. It also restores any new or edited files. Now, when you re-send the improved prompt, you're starting from a clean slate.
- You ride the happy path. With better context, the model delivers exactly what you want, often better than what you would have gotten through multiple rounds of correction.
A Note on Plan vs. Act Mode: This workflow is powerful in both of Cline's modes. In Plan Mode, you can use it to refine a plan that's getting off track. In Act Mode, it's essential for correcting an execution that has started to diverge from your intended plan. The principle is the same: reset the context and provide a better instruction.
Why this works
The research is clear: LLMs perform best with complete context delivered upfront. This reframes the problem: you're not debugging the model's code, you're debugging your prompt. The best way to fix a bad prompt isn't to patch it through a polluted conversation; it's to rewrite it with the benefit of hindsight.
Message checkpoints make this workflow seamless. They remove the friction of starting over, allowing you to work with the grain of the model instead of fighting against it. By embracing the checkpoint-and-restart workflow, you're hacking the happy path, using the model's strengths, and creating the conditions to reclaim that 39% performance gap.
-Nick
Ready to hack your own happy path? Download Cline and experience how checkpoints transform your development workflow. Share your checkpoint success stories with our community on Discord and Reddit.



