Inside Cline's Framework for Optimizing Context, Maintaining Narrative Integrity, and Enabling Smarter AI


Effective context management is the backbone of productive collaboration with AI coding assistants. As conversations with Cline evolve and become ever more complex, determining how to handle the persistent issue of limited room in the context window becomes increasingly more important – as well as ensuring narrative integrity is maintained during extended conversations.
Why focus on token efficiency? Because we're learning that smarter context management is fundamental to performance. Trimming unnecessary context improves affordability, yes, but more importantly, it reinforces the narrative integrity needed for accurate coding.
Our new generalizable framework
We've built a new framework for improving how we handle what stays in the context window to jointly minimize token usage and optimize Cline's capabilities. For this, we've started with building out key features which address the critical issues we've seen users mention – maintaining narrative integrity after truncating conversation history and handling the large number of redundant file reads which fill up the context window.
Let's look at how we manage file reads in a bit more detail. When a user is working on the same codebase for an extended period of time, Cline ends up loading the same file many times, as a function of its tool calls and user inputs. These include calls to read_file, replace_in_file, write_to_file, and @ mentions. This is important for giving Cline access to the latest versions of each file as users continue to edit it, ask questions about it, work with it, etc. However, this also means the context window ends up cluttered with multiple old versions of the same file.
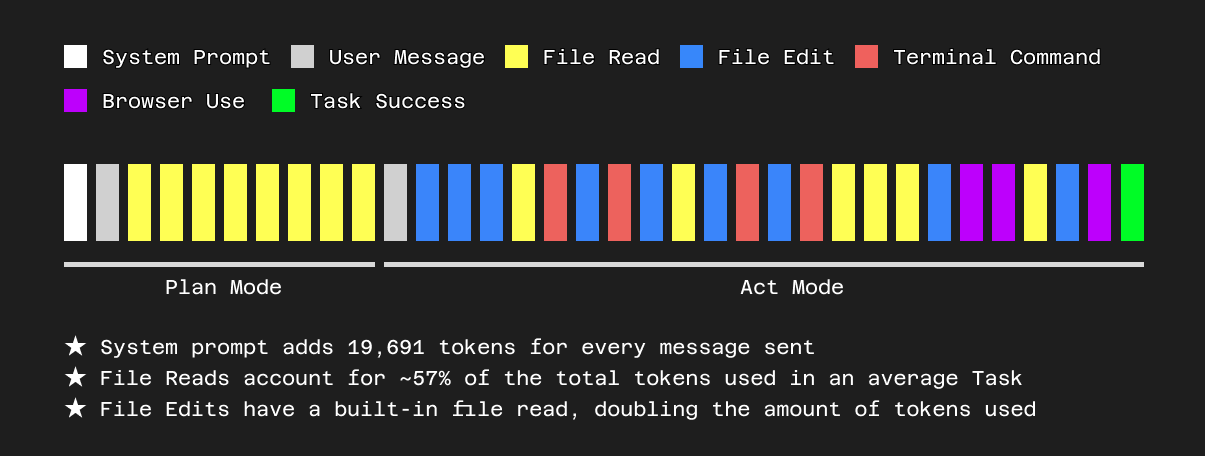
This not only wastes precious space in the context window, but from what we've seen in our internal evals, can lead to certain LLM models having a harder time identifying correct chunks of the file for editing, ultimately leading to higher error rates with tools like replace_in_file. As the first step in our new context management framework, we've begun removing these older outdated file reads, leaving only the latest version of the file in context, while retaining the overall narrative integrity of the conversation. We've started with a very conservative approach for determining whether we still need to truncate old messages after removing unnecessary file reads, as we want to also maximize prompt caching to reduce user costs.
This careful balance extends to prompt caching. While removing outdated file reads is a clear win, aggressively truncating older messages can break the cache, potentially increasing costs on subsequent turns. Our current approach prioritizes removing file redundancy first, maximizing cache hits and cost savings for users where possible.
We ultimately designed this framework to be extensible, allowing for future context management improvements while integrating smoothly with other features like checkpointing.
Other context things
We are also iterating on other approaches for reducing token usage, including altering our system prompt. Cline has set the standard among AI coding agents for how MCP servers can be built and used. But previously some instructions related to working with MCP servers inflated the length of our system prompt. Up to now, we've used 30% of our system prompt for instructing Cline on how to build and use MCP servers.
This static set of instructions are being replaced with a load_mcp_documentation tool. This allows Cline to retrieve the ~8,000 tokens of documentation only when explicitly required for MCP-related tasks, eliminating the per-request overhead.
Some stuff I'm excited about
We've identified other similar approaches to improve our management of the context window, but why stop there? What if Cline is in parallel selecting the most important messages to maintain in context? What if Cline is summarizing its conversation history with the user in a way which maximizes efficiency and uses the minimal number of tokens necessary to fully complete a user's task? Etc., etc., we have a lot of stuff we're working on :)
We are committed to continue maximizing both efficiency and performance, and what's even better is that it's not a tradeoff: efficiency, affordability, and performance are all aligned. I'm excited for what's coming next.
Ty frens for supporting Cline.
-Toshi



