Chapter 2: LLM Benchmarks
Learn how to interpret LLM benchmarks—coding, domain, and tool-use—to match scores with your development needs.


What Benchmarks Actually Measure
Benchmarks in the language model world serve a similar purpose to standardized tests in education: they provide a consistent way to compare different models across specific capabilities. However, just as a high SAT score doesn't guarantee success in every college major, a high benchmark score doesn't guarantee a model will excel at every task you throw at it.
The key insight is that different benchmarks test different aspects of intelligence and capability. Some focus on pure coding ability, others on domain-specific knowledge, and still others on the ability to use tools effectively. Understanding these distinctions helps you match benchmark performance to your actual needs in Cline.
Coding Capability Benchmarks
Since coding represents the primary use case for most Cline users, benchmarks that measure programming ability deserve special attention. These tests evaluate how well models can understand existing code, generate new code, and solve programming problems.
SWE-Bench stands out as particularly relevant because it tests models against real-world software engineering challenges. Rather than using artificial coding problems, SWE-Bench curates actual GitHub issues from popular open-source projects. When a model performs well on SWE-Bench, it demonstrates the ability to understand complex codebases, identify bugs, and implement fixes that work in real production environments.
This real-world focus makes SWE-Bench results highly predictive of how a model will perform when you ask Cline to fix bugs, implement features, or refactor existing code. The benchmark tests exactly the kinds of tasks you're likely to encounter in your daily development work.
However, SWE-Bench has an important limitation: data contamination. Some models may have encountered the specific GitHub issues used in the benchmark during their training, giving them an unfair advantage. This is why SWE-Bench Verified exists – it manually verifies that the test cases represent genuine problem-solving rather than memorization.
Complementary coding benchmarks like HumanEval, LiveCodeBench, and BigCodeBench each test different aspects of programming ability. HumanEval focuses on function-level code generation from natural language descriptions. LiveCodeBench tests against recent programming problems to minimize contamination. BigCodeBench evaluates performance on larger, more complex coding tasks that require understanding multiple files and systems.
When choosing a model for coding-heavy Cline usage, looking for consistent performance across multiple coding benchmarks provides a more reliable picture than relying on any single score.
Domain-Specific Knowledge Benchmarks
Many Cline use cases extend beyond pure programming into specialized domains that require deep subject matter expertise. If you're building healthcare applications, financial modeling systems, or scientific computing tools, your model needs more than just coding ability – it needs domain knowledge.
MMLU (Massive Multitask Language Understanding) tests models across 57 different academic subjects, from elementary mathematics to professional law and medicine. A model that scores well on MMLU's biology sections is more likely to understand the nuances of healthcare data processing. Strong performance on mathematics sections suggests better capability for financial modeling or scientific computing applications.
GPQA (Graduate-Level Google-Proof Q&A) focuses specifically on graduate-level questions in biology, physics, and chemistry. These questions are designed to be difficult even for experts in the field, making GPQA performance a strong indicator of deep domain understanding.
AIME (American Invitational Mathematics Examination) tests advanced mathematical reasoning. For applications involving complex algorithms, optimization problems, or mathematical modeling, AIME performance can predict how well a model will handle the mathematical aspects of your development tasks.
The key insight is matching benchmark domains to your application domains. If you're building financial software, prioritize models with strong performance on economics and mathematics benchmarks. For healthcare applications, look for models that excel in biology and medicine evaluations.
Tool Usage and MCP Capabilities
One of Cline's most powerful features is its ability to integrate with external tools and services through the Model Context Protocol (MCP). This capability enables everything from web scraping and browser automation to real-time documentation and extended memory systems.
However, not all models excel at tool usage. Some struggle with the precise formatting required for tool calls, others make inconsistent decisions about when to use tools, and still others fail to chain multiple tool calls together effectively.
Benchmarks that measure tool usage capability are still evolving, but they typically test whether models can correctly format tool calls, choose appropriate tools for given tasks, and maintain consistency across multiple interactions. These benchmarks often involve scenarios like "use the web search tool to find information about X, then use the calculator tool to perform computation Y based on that information."
For Cline setups that rely heavily on MCP integrations, tool usage benchmark performance becomes a critical selection criterion. A model that excels at pure coding but struggles with tool calls will create frustrating experiences when you need it to interact with external services.
The Limitations of Benchmarks
While benchmarks provide valuable guidance, they only tell part of the story. Benchmark performance represents capability under controlled conditions, but your actual Cline usage involves unique codebases, specific requirements, and particular workflows that no benchmark can fully capture.

Consider two models with similar SWE-Bench scores. One might excel at Python web development while struggling with embedded systems programming. The other might handle systems programming beautifully but produce verbose, hard-to-maintain web application code. The benchmark scores alone wouldn't reveal these differences.
This is why experimentation in your own environment remains crucial. Benchmarks can help you narrow down your choices to models with relevant capabilities, but only hands-on testing can reveal which model works best for your specific use cases.
A Practical Evaluation Strategy
The most effective approach combines benchmark analysis with practical experimentation. Start by identifying your primary Cline use cases: Are you mainly fixing bugs and implementing features? Working in specialized domains? Relying heavily on MCP integrations?
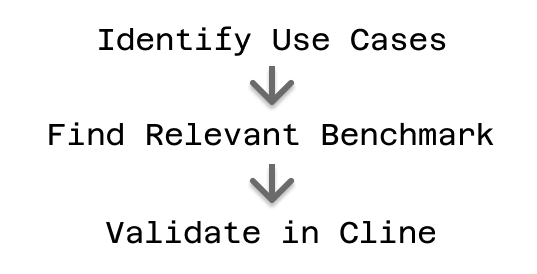
Once you understand your use cases, look for models that perform well on relevant benchmarks. For coding-focused work, prioritize SWE-Bench, HumanEval, and related programming benchmarks. For domain-specific applications, examine MMLU performance in relevant subject areas. For MCP-heavy workflows, seek out tool usage benchmark results.
After identifying promising candidates based on benchmark performance, take advantage of Cline's model-agnostic design to test them in your actual environment. Try the same complex task with different models and observe not just the quality of results, but also the approach each model takes, the consistency of its outputs, and how well it integrates with your existing workflow.
This combination of benchmark-informed selection and practical testing helps you find models that not only score well on standardized tests but also excel at your specific development challenges.
The Evolution of Understanding
As you gain experience with different models in your Cline environment, you'll develop intuitions that go beyond what any benchmark can measure. You'll learn which models handle your coding style well, which ones integrate smoothly with your preferred frameworks, and which ones provide the right balance of capability and cost for your workflow.
This experiential knowledge complements benchmark data to create a comprehensive understanding of model capabilities. The benchmarks provide the initial framework for evaluation, while your hands-on experience fills in the details that matter most for your specific use cases.
Ready to apply benchmark insights to your model selection process? Start by identifying which benchmarks align with your primary Cline use cases, then experiment with top-performing models in your actual development environment.
For detailed benchmark comparisons and model selection guidance, visit our documentation. Share your benchmark experiences and learn from other developers' model evaluations on Reddit and Discord.



