Chapter 4: LLM Providers
Explore how Cline’s model-agnostic design lets you route tasks via providers, aggregators, or local models—optimizing cost, speed & privacy.

The Model-Agnostic Philosophy
Cline's design philosophy centers on model agnosticism – the principle that you shouldn't be locked into any particular language model or provider. This flexibility ensures that your development workflow isn't dependent on a single company's offerings, pricing decisions, or service availability.
This approach provides several crucial benefits. You can switch between models based on task requirements, take advantage of new models as they become available, avoid vendor lock-in that might limit your options, and optimize for different priorities like cost, speed, or capability depending on your current needs.
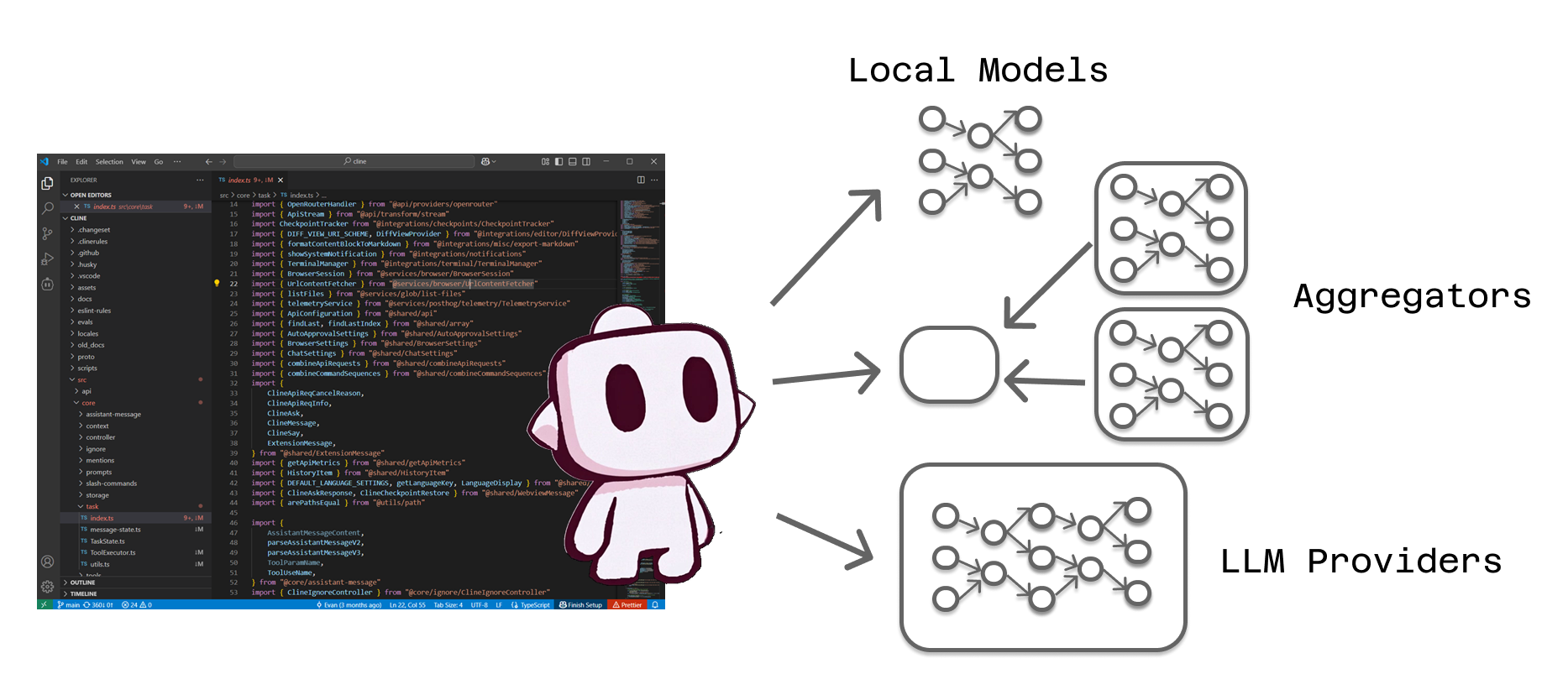
The model-agnostic design means Cline must be able to communicate effectively with three fundamentally different types of endpoints: direct connections to LLM providers, routing through aggregator services, and local models running on your own hardware.
LLM Provider: Direct to Source
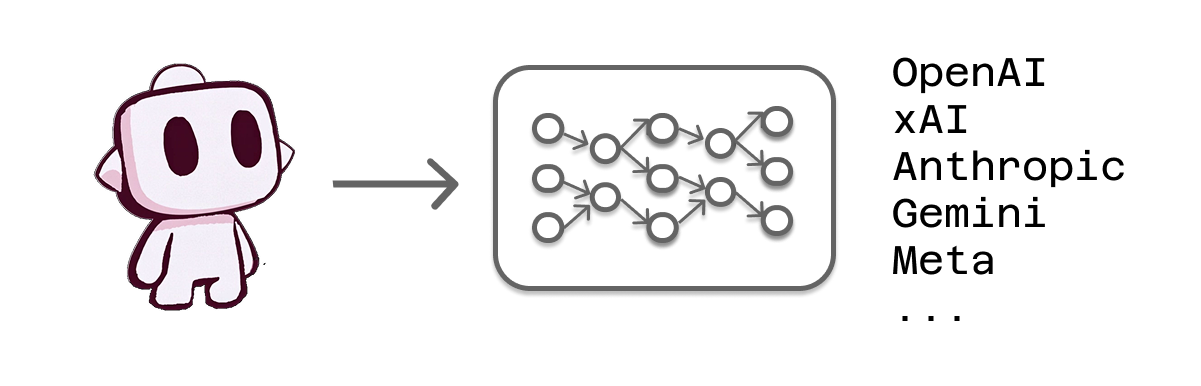
The most straightforward approach involves connecting Cline directly to language model providers like Anthropic, OpenAI, Google (Gemini), or xAI. In this configuration, your requests travel directly from Cline to the provider's servers, where they're processed by the company's models and returned to you.
Direct connections offer several advantages. You get the most up-to-date versions of models as soon as providers release them. There's no intermediary that might introduce delays or additional costs. You have direct access to provider-specific features and optimizations. The communication path is as simple and direct as possible.
This approach works well when you have clear preferences for specific providers, want guaranteed access to the latest model versions, or need to take advantage of provider-specific features like custom fine-tuning or specialized model variants.
However, direct connections also mean managing separate accounts, billing relationships, and API keys for each provider you want to use. If you like to experiment with models from different companies, this can become administratively complex.
Aggregator: The Universal Router
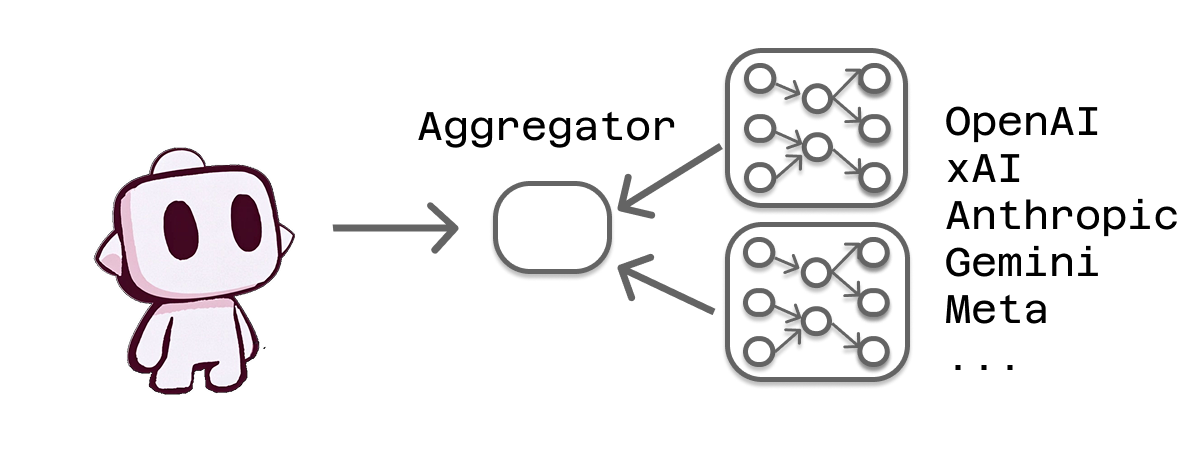
LLM aggregators serve as universal routers that provide access to multiple model providers through a single interface. Instead of managing relationships with individual providers, you work with the aggregator, which handles routing your requests to the appropriate destination.
Think of aggregators as travel agents for AI requests. Just as a travel agent can book flights on different airlines, hotels from various chains, and rental cars from multiple companies through a single interface, aggregators can route your requests to models from different providers while presenting you with a unified experience.
This approach offers compelling advantages for many users. You can experiment with models from different providers without setting up multiple accounts. Aggregators often provide credit-based systems that let you try various models without committing to specific providers. Many aggregators offer additional features like request analytics, usage tracking, or cost optimization tools.
Some aggregators go beyond simple routing to offer privately hosted models. This option appeals particularly to enterprise users who want the flexibility of multiple model options while maintaining control over where their data is processed. Instead of sending requests to public provider endpoints, these aggregators can route requests to models running on private infrastructure.
The aggregator approach shines when you want maximum flexibility to experiment with different models, prefer simplified billing and account management, or need access to models that might not be directly available from providers.
Local Models: Direct to Model
The third option involves running language models directly on your own hardware using applications like LM Studio, Ollama, or similar local inference engines. In this configuration, you become your own LLM provider, with Cline connecting to models running on your local machine.
Local deployment offers unique advantages that appeal to specific use cases and priorities. All your interactions with Cline remain completely private, never leaving your local network. The only ongoing cost is electricity to power your hardware. You have complete control over model versions, configurations, and availability. There's no dependency on external services or internet connectivity for basic functionality.
This approach particularly appeals to developers working on sensitive projects, those in environments with limited internet access, or anyone who prioritizes data privacy above all other considerations. It's also attractive for high-volume users who want to avoid per-token pricing models.
However, local deployment requires significant technical expertise and hardware investment. You need sufficient computational resources to run models effectively, which often means high-end GPUs and substantial memory. You're responsible for model updates, maintenance, and troubleshooting. The selection of available models may be more limited than what's offered by commercial providers.
Strategic Routing Decisions
The flexibility to choose between these three approaches enables sophisticated strategies that optimize for different priorities across different types of work. Many Cline users develop hybrid approaches that leverage the strengths of each routing method.

For example, you might use local models for exploratory work and sensitive projects, direct provider connections for production work that requires the latest capabilities, and aggregators for experimentation with new models or providers.
Some developers route different types of tasks to different endpoints based on requirements. Quick iterations and brainstorming might go to fast local models, complex architectural decisions to premium provider models, and routine maintenance tasks to cost-effective aggregator options.
The key insight is that routing decisions don't have to be permanent or universal. Cline's flexibility allows you to match routing strategies to specific tasks, projects, or phases of development work.
Configuration and Management
Cline's settings interface provides straightforward management of these different routing options. You can configure multiple providers, aggregators, and local endpoints, then switch between them as needed. This configuration flexibility extends to Cline's Plan and Act modes, where you can save different routing preferences for different types of work.
The ability to easily reconfigure routing means you can adapt to changing circumstances – new model releases, pricing changes, availability issues, or evolving project requirements – without disrupting your development workflow.
This configuration flexibility also supports experimentation and optimization. You can test the same task across different routing options to understand the trade-offs in cost, speed, and quality for your specific use cases.
The Power of Choice
Understanding these routing options empowers you to make strategic decisions about how your Cline interactions are processed. Rather than being constrained by a single approach, you can choose the routing method that best aligns with your priorities for each type of work.
This choice extends beyond simple technical considerations to encompass broader strategic decisions about data privacy, cost management, vendor relationships, and operational flexibility. The routing decision becomes part of your overall development strategy rather than just a technical configuration detail.
Ready to explore different routing options for your Cline setup? Start by evaluating your priorities around cost, privacy, flexibility, and performance, then experiment with different routing approaches to find what works best for your workflow.
For detailed guidance on configuring providers and routing options, visit our documentation. Share your routing strategies and learn from other developers' approaches on Reddit and Discord.



