The End of Context Amnesia: Cline's Visual Solution to Context Management


Ever stared at Cline wondering if it's about to hit a wall? You're deep in a complex refactoring task, and suddenly he seems to "forget" what you were discussing just moments ago. If this sounds familiar, you're running into one of the most common yet least understood aspects of AI coding assistants: context windows.
Today, we're introducing a new feature in Cline that makes this invisible limit visible: the Context Window Progress Bar.
What's a Context Window, Anyway?
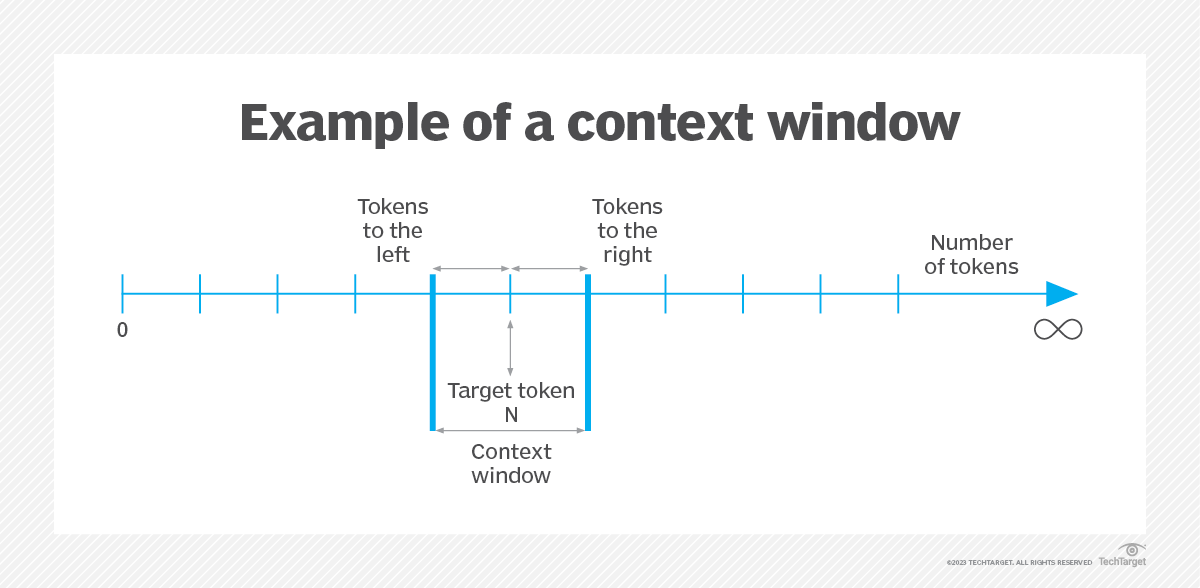
Think of a context window as your AI's working memory. Just like how you can only hold so many things in your head at once, AI models have a limit to how much information they can process at a time. This limit is measured in tokens (roughly 3/4 of a word in English).
Here's what our new progress bar shows you:

Let's break this down:
- ↑ shows input tokens (what you've sent to the LLM)
- ↓ shows output tokens (what the LLM has generated)
- The progress bar visualizes how much of your context window you've used
- The total shows your model's maximum capacity (e.g., 200k for Claude 3.5-Sonnet)
Making the Most of Context Windows
Why Context Management Matters
Having a visible context window meter transforms how you work with Cline in three major ways:
- No More Surprises
- See exactly when you're approaching limits
- Prevent unexpected "amnesia" during critical tasks
- Plan your work around available context
- Smarter Resource Management
- Choose the right model for your task size
- Claude (200k tokens): Perfect for large projects
- DeepSeek (64k tokens): Ideal for focused tasks
- Optimized Workflows
- Structure conversations efficiently
- Clear context strategically
- Maintain productivity without interruptions
Practical Context Management Strategies
Monitor Your Context Window
Keep a close eye on usage during:
- Large refactoring tasks
- Codebase analysis sessions
- Complex debugging operations
Take Action at Key Thresholds
When approaching 70-80% capacity:
- Consider a fresh start
- Break tasks into smaller chunks
- Focus queries on specific components
- Document key decisions
Choose the Right Model
Different models suit different tasks:
Claude (200k tokens)
- Best for: Large projects
- Features: Extended conversations
- Use case: Full codebase analysis
DeepSeek (64k tokens)
- Best for: Focused tasks
- Features: Fast responses
- Use case: Single-file operations
Other Models
- Check the progress bar for limits
- Choose based on task complexity
- Balance speed vs. context needs
Advanced Management Techniques
The Memory Bank Pattern
For complex projects:
- Maintain Documentation
- Structure project information
- Keep reference materials handy
- Document architectural decisions
- Strategic Task Planning
- Break work into context-sized chunks
- Plan session boundaries
- Preserve critical context
- Session Management
- Start fresh at logical boundaries
- Maintain context for related tasks
- Document session outcomes
Best Practices for Long Sessions
- Proactive Monitoring
- Watch the progress bar
- Reset at 70-80% usage
- Start fresh sessions strategically
- Structured Interactions
- Begin with clear context
- Keep related tasks together
- Document important decisions
- Smart Reset Timing
- After completing major features
- When switching contexts
- If responses become inconsistent
Think of context like a whiteboard – sometimes you need to erase and start fresh to stay organized, even if you technically have more space. The key is being proactive rather than reactive in your context management.
Under the Hood: How Cline Manages Context
For the technically curious, let's peek under the hood at how Cline manages context windows. What looks simple on the surface is actually a sophisticated system that balances performance, conversation coherence, and memory management.
Smart Buffer Management
First, let's look at how Cline prevents context overflow. The core of this system is a clever formula:
maxAllowedSize = Math.max(contextWindow - 40_000, contextWindow * 0.8)
This ensures you always have either:
- A fixed 40,000 token buffer (for larger context windows), or
- 20% of your total context as buffer (for smaller windows)
-->Whichever gives you more headroom. This adaptive approach means you'll always have enough space for new interactions while maximizing usable context.
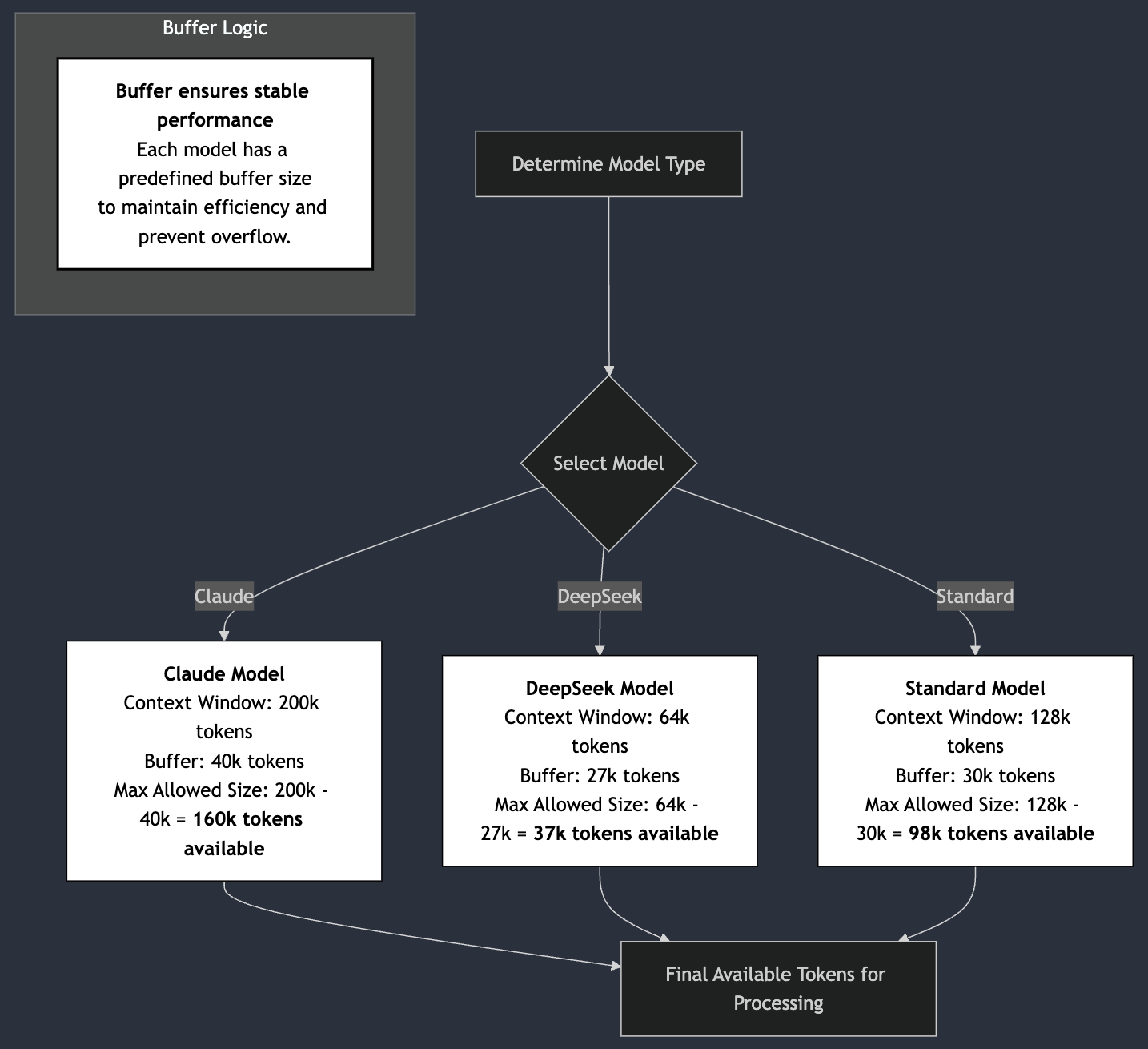
Model-Specific Optimization
Different AI models have different needs, so Cline adapts its approach for each:
Claude Models (200k tokens)
maxAllowedSize = contextWindow - 40_000 // 160k usable tokens
- Generous 40k token buffer
- Optimized for long-form conversations
- Full prompt caching support
DeepSeek Models (64k tokens)
maxAllowedSize = contextWindow - 27_000 // 37k usable tokens
- Specialized 27k buffer for stability
- Perfect for focused, shorter tasks
Standard Models (128k tokens)
maxAllowedSize = contextWindow - 30_000 // 98k usable tokens
- Balanced approach
- Ideal for most development tasks
Smart Truncation System
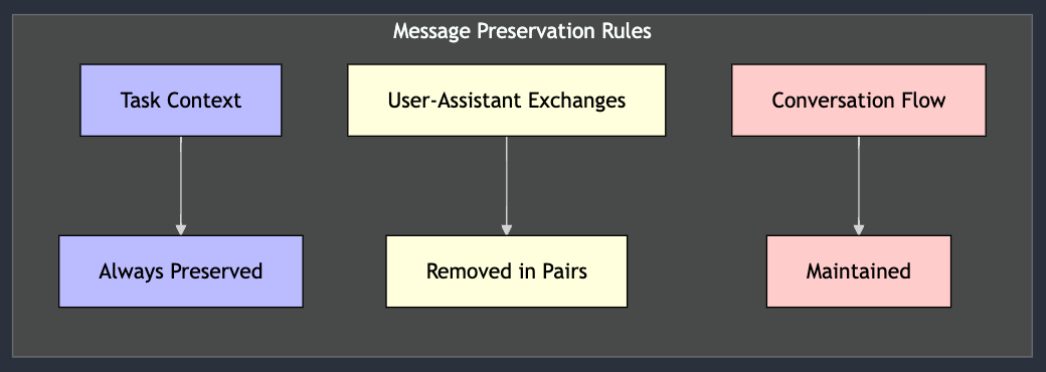
When you approach the context limit, Cline doesn't just delete messages randomly. Instead, it uses a sophisticated algorithm that:
1. Preserves Critical Context
// Always keeps the initial task message
const truncatedMessages = [messages[0]]
This ensures you never lose your original task context or project structure information.
2. Model-Aware Truncation
When switching between models with different context window sizes, Cline needs to be smart about how it handles existing conversations. This is particularly important when moving from a model with a larger context window to one with a smaller one:
// Example: Switching from Claude (200k) to DeepSeek (64k)
// requires more aggressive truncation to fit within new constraints
if (switching to smaller context model) {
keep = "quarter" // Remove 75% to ensure fit
} else {
keep = "half" // Standard 50% reduction
}
This means:
- Switching from Claude (200k) to DeepSeek (64k) requires removing more history
- The system adapts its truncation strategy based on the target model's capacity
- Memory management is proactive, anticipating the new model's constraints
This model-aware approach helps prevent issues when switching between different AI providers while maintaining conversation coherence.
3. Maintains Conversation Flow
messagesToRemove = Math.floor((messages.length - startOfRest) / 4) * 2
By removing messages in pairs, we maintain the natural flow of user-assistant conversation patterns.
Prompt Caching Magic
Finally, all of this works in harmony with our prompt caching system:
- Caches survive truncation operations
- Important context can be retrieved without eating into your window space
- You get longer effective conversations without sacrificing performance
This careful balance of buffer management, model-specific handling, and intelligent truncation is what makes Cline's context management both powerful and user-friendly.
The Bottom Line
Context windows are like RAM for your AI assistant – crucial but limited. With our new progress bar, you're no longer flying blind. You can see exactly how much "memory" you're using and plan accordingly.
If you're already using Cline, we'd love to hear how you're using the context window progress bar. Share your experiences in our subreddit or join our Discord!


